En este serie de posts voy a explicar cómo he escrito un generador de blogs desde 0 usando Elixir y la librería estándar de Erlang. ¿Mi motivación?, aprender más. ¿Qué problema tiene en picarse un servidor http de 0 y un transpilador de Markdown a HTML?
Está dividido en dos partes, esta primera vamos a explorar el servidor HTTP.
Qué vamos a ver en esta serie de posts
- Crear nuestro servidor HTTP
- Leer peticiones y mostrar resultados
- Responder de forma concurrente
- Transpilar Markdown hacía HTML
- Cómo crear templates para meter CSS y otros
Qué es un generador estático de sitios?
Escribir blogs directamente en HTML y CSS puede ser muy costoso, especialmente cuando la estructura del sitio es compleja. Si inspeccionas esta misma web verás que está escrita en un HTML extremadamente simple (en parte es decisión mia) pero imaginemos que tenemos un blog muchísimo más complejo con enlaces, tags, menú multinivel, etc. Entonces la cosa se empieza a complicar.
Sin embargo, es mucho más sencillo escribir posts en Markdown y transpilarlos a HTML de esta forma podemos escribir en un lenguaje de marcado mucho más simple que HTML.
Este trabajo de transpilar y poner el html bonito con su CSS se llaman Static Site Generators, donde nuestra página sólo descarga contenido y no acepta ninguna petición ni nada relevante por parte del cliente, simplemente nos piden una ruta y nuestro servidor HTTP se encarga de entregar.
Qué opciones ofrece el mundo open source?
- Serum
- Franklin
- Gatsby
- Hexo
- Eleveny
- Pelican
- Zola
- Hugo (esta web)
- Jekyll
Existen muchos de ellos y en distintos lenguajes el mio se llama Personal
Personal
Personal es un proyecto que ha durado 1 semana motivado por boot.dev y ThePrimegen donde hacen proyectos muy interesantes para forzarte a salir un poco de tu ámbito. En mi caso decidí además hacerlo con 0 dependencias por darle un poco de emoción. Además, al realizarlo desde cero uno aprecia muchísimo más el gran trabajo que hacen los contribuidores opensource porque como veremos todo es relativamente simple pero muy costoso de realizar.
HTTP 1.1 Server
Cómo ya hemos dicho esto lo vamos a programar a pelo. Así que lo primero es abrir sockets. Para ello usaremos el módulo gen_tcp, este módulo nos va a dar absolutamente todo lo que necesitamos para montar nuestro server.
No voy a entrar en mucho detalle sobre cómo funciona un servidor HTTP, pero lo primero que tenemos que hacer es bindear a un puerto y obtener nuestro “Listen Socket”
defp accept(port) do
{:ok, listen_socket} = :gen_tcp.listen(
port,
[
:binary,
packet: :line,
active: false,
reuseaddr: true,
nodelay: true,
backlog: 1024
]
)
Logger.info("Listening port: #{port}")
loop(listen_socket)
end
Esto interactura con el Stack TCP/IP donde se crea un buffer de 1024 espacios para conexiones pendientes (backlog). Para entender un poco mejor, cada vez que alguien hace una petición a nuestro puerto, esta se almacena en el buffer esperando a ser aceptada, reducir o aumentar este número afecta dramáticamente al throughput. (puedes hacer pruebas de becnhmark y verás la diferencia :3)
Como acabo de explicar tenemos un buffer, pero ahora tenemos que aceptar estas conexiones una a una las cuales van a ser quitadas de este buffer, para esto tenemos que ejecutar en bucle infinito el siguiente código.
defp loop(listen_socket) do
case :gen_tcp.accept(listen_socket) do
{:ok, socket} ->
Personal.Worker.work(socket)
{:error, reason} ->
Logger.error("Failed to accept connection #{inspect(reason)}")
end
loop(listen_socket)
end
Es muy importante considerar en este momento el uso de concurrencia ya que si lo pensamos bien tenemos
una función ejecutando en bucle infinito :gen_tcp.accept/1 y Personal.Worker.work(socket) por lo que
si estas funciones son lentas ya nos podemos imaginar el mega cuello de botella aceptando peticiones. Idealmente queremos aceptar conexiones y servirlas de forma paralela sin que una bloquee la otra.
Por lo que llegados a este punto tenemos que considerar la arquitectura de nuestro servidor, en mi caso es algo similar a esto:
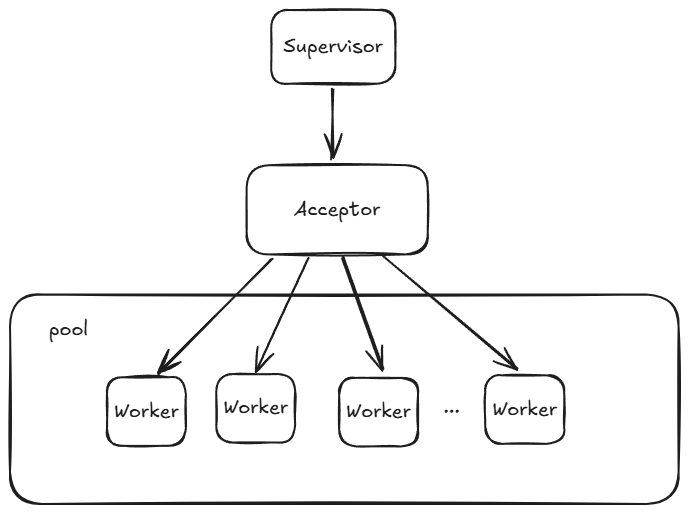
En mi caso no es exáctamente así ya que no he creado una pool simplemente lanzo procesos. Lo importante a destacar
aquí es que tenemos un Proceso llamado Acceptor que es el que va aceptando las conexiones, y el Worker va a ser el encargado de crear un proceso por conexión para servir la petición.
Aquí vemos el código principal del worker:
def work(socket) do
fun = fn ->
case :gen_tcp.recv(socket, 0) do
{:ok, data} ->
{code, body} = handle_request(data)
response = "#{@http_ver} #{code}\r\n#{@server}\r\nContent-Type: text/html\r\n\n#{body}\r\n"
:gen_tcp.send(socket, response)
:gen_tcp.close(socket)
{:error, reason} ->
Logger.error("Failed to read socket socket #{inspect(reason)}")
:gen_tcp.close(socket)
end
end
pid = spawn(fun)
:gen_tcp.controlling_process(socket, pid)
end
Nuestro Acceptor sólo ejecuta la declaración de la fun, crea otro proceso con spawn/1, donde le pasamos
la fun y le decimos al stack usando :gen_tcp.controlling_process(socket, pid) que el socket que hemos obtenido aceptando con :gen_tcp.accept ahora su dueño es el proceso que acabamos de crear.
Por lo que nuestro Acceptor puede continuar en su loop aceptando conexiones y el nuevo proceso continuará sirviendo la petición.
Como nota tengo que añadir que esta no es la mejor forma de manejar este problema ya que levantamos procesos sin ningún tipo de control y además la declaración de la fun se ejecuta en runtime por lo que esto puede dar problemas en función del caso de uso.
El mundo real es mucho más complejo y la realidad es que terminamos usando librerías de 3eros. En el caso de Elixir estas librerias suelen ser:
- Ranch usada por
- Cowboy usado por
- plug_cowboy usada por
- Plug usada por
- Phoenix.
- (Podría seguir)
Además ahora tenemos nuevas librerías cómo Bandit que a su vez tiene su árbol de dependencias.
Estas librerías si que son ejemplos sobre cómo tienes de trabajar en producción, pero nuestro pequeño proyecto sirve para que entiendas por qué existen estas librerías y por qué la gente las mantiene durante tantos años.
HTTP 1.1 Request!
Muy bien, ya tenemos el socket del cliente donde podemos leer y escribir datos, ahora pasamos a trabajar en el mundo de las Requests.
Las peticiones de HTTP son bastante sencillas, ya que es las obtenemos en texto plano donde nos pueden llegar varias líneas separadas con saltos de línea.
Un ejemplo de una petición sin headers sería esto:
GET /styles/style.css HTTP/1.1\r\n
Es ahora problema nuestro leer la línea, parsearla correctamente y saber qué hacer con ella. En este caso podemos ver que es una petición GET y quiere obtener la hoja de estilos en esta ruta indicada.
En nuestro caso solo he implementado GET
def handle_request("GET " <> rest) do
path =
rest
|> String.split(" ")
|> List.first()
body = FileReader.get_file(path)
if body == nil do
{"404 Not Found", ""}
else
{"200, OK", body}
end
end
def handle_request(_) do
{"405 Method Not Allowed", ""}
end
Como podemos ver sacamos el path, lo buscamos en FileReader y devolvemos una respuesta adecuada. NOTA: es muy importante el cómo leemos los datos ya que esto puede generar fallas de seguridad muy pepinas. En el caso de Personal veremos que precachea los ficheros en memoria.
Para enviar datos sólo tenemos que seguir el formato de una Reponse similar a esto
response = "#{@http_ver} #{code}\r\n#{@server}\r\nContent-Type: text/html\r\n\n#{body}\r\n"
Y finalmente ejecutar
:gen_tcp.send(socket, response)
:gen_tcp.close(socket)
Estas dos últimas líneas, enviamos la respuesta y cerramos el socket, terminando a su vez la ejecución del proceso que controla el socket.
Como podemos ver en este sencillo caso, aquí faltan miles de cosas distintas, qué pasas tema headers, distintas peticiones http, etc. Hay un mundo de especificaciones por descubrir! rfc9110 have fun!
Getting the body!
El objetivo de todo servidor HTTP es que nuestro cliente obtenga cualquier tipo de dato que nosotros queramos hacer visible pero esto tiene que ser hecho de forma segura. Imagina que alguien puediera hacer algo similar a GET /etc/passwd y nuestro servidor diga, “Claro sin problemas aquí tienes…”.
Para evitar esto y sabiendo que esto es un pequeño blog, directamente voy a evitar que las peticiones GET tenga que hacer llamadas de sistema para leer. Para ello, cuando el servidor se levante va a leer todos datos de una carpeta en concreto generará una estructura de datos para acceder a ellos.
En nuestro caso FileReader define una carpeta que he llamado static que almacena toda la información final que nuestro blog pueda ofrecer. Al mismo tiempo, la estructura de carpetas va a ser la misma estructura de las peticiones HTTP.
Por ejemplo si nuestra estructura tiene esta forma:
static/
├─ images/
├─ styles/
│ ├─ style.css
├─ blog/
├─ index.html
Para obtener style.css o index.html las peticiones deberían de ser:
GET /styles/style.css HTTP/1.1\r\n
GET / HTTP/1.1\r\n
En el caso de FileReader construye un Mapa donde cada key es una carpeta y los ficheros dentro de esta carpeta tienen como key el nombre del fichero y como valor el contenido del mismo.
%{
"static" => %{
"images" => %{
"sample.webp" => <<82, 73, 70, 70, 214, 10, 0, 0, 87, 69, 66, 80, ...>>
},
"index.html" => "<html>...</html>",
"styles" => %{
"style.css" => "/* css content */"
}
}
}
De modo que si en varible data tenemos el mapa anterior, para obtener sample.webp tenemos que ejecutar
data["static"]["images"]["sample.webp"]
En mi opinión, este méotod es bastante sencillo. Obviamente si el script que construye este mapa accede a recursos fuera de static tendríamos un problema. Pero fuera de eso, una vez escrita la estructura no va a poder ser actualizada hasta reiniciar el servidor (se puede cambiar en runtime de todas formas)
En mi caso la estructura es almacenada en un persistent_term que ofrece las lecturas más rápidas en elixir despues de declarar variables directamente en código.
Con esto termina la parte de servidor HTTP, en el siguiente post vamos a ver como construimos el HTML desde un Markdown y como se hace el “bundle” hacia la carpeta “static”